What Does Cloud Native Really Mean?
Kyle Brown and Kim Clark
Note: This is part 1 of a multipart series You can jump to Part 2, Part 3, Part 4, or Part 5.
All too often, conversations around cloud native dive straight into technology choices like containerization and microservices. These are definitely potential ingredients of a cloud native project, but they are most certainly not the whole picture. Across this article series we will explore cloud native from several different angles, including technology and infrastructure of course, but also architecture, design, and perhaps most overlooked, people and processes. Put in the simplest possible terms, cloud native means not just moving to cloud, but fully leveraging the uniqueness of cloud infrastructure and services to rapidly deliver business value.
Cloud native concepts existed before the term itself came into use. In a sense, cloud native began when public cloud vendors started providing easy and affordable access to elastic instances of compute power. The question then became, how can you write applications to capitalize on the flexibility of this new infrastructure, and what business benefits can you achieve as a result?
Cloud native methods and technology have changed a lot over the last ten years, and are still evolving, but the core technical and business objectives that cloud native applications set out to achieve have remained the same. These include:
- Agility and Productivity: Enable rapid innovation that is guided by business metrics. De-risk maintenance and keep environments current.
- Resilience and Scalability: Target continuous availability that is self-healing and downtime-free. Provide elastic scaling and the perception of limitless capacity.
- Optimization and Efficiency: Optimize the costs of infrastructural and human resources. Enable free movement between locations and providers.
We will break these goals down more in a later article when we look back at the “why” of cloud native, but hopefully even from this simplistic definition, it should be clear that cloud native is broader than simply a move to a new type of infrastructure. However, while these goals are accurate, it’s hard to see they apply to cloud native specifically. We need to do more to define what cloud native actually means.
Popular reference points related to cloud native, such microservices, and older manifestos such as 12factor apps might lead you to conclude that cloud native is a description of an architectural style, and the other choices follow from that. There is certainly some truth in that and cloud native architectures definitely do exist. However, in order to succeed with cloud native, companies must take a more holistic view. Alongside architectural and infrastructural decisions, there are also organizational and process decisions. That has led us to a key realization:
Technology alone cannot attain business outcomes
The diagram below shows how these decisions interact.
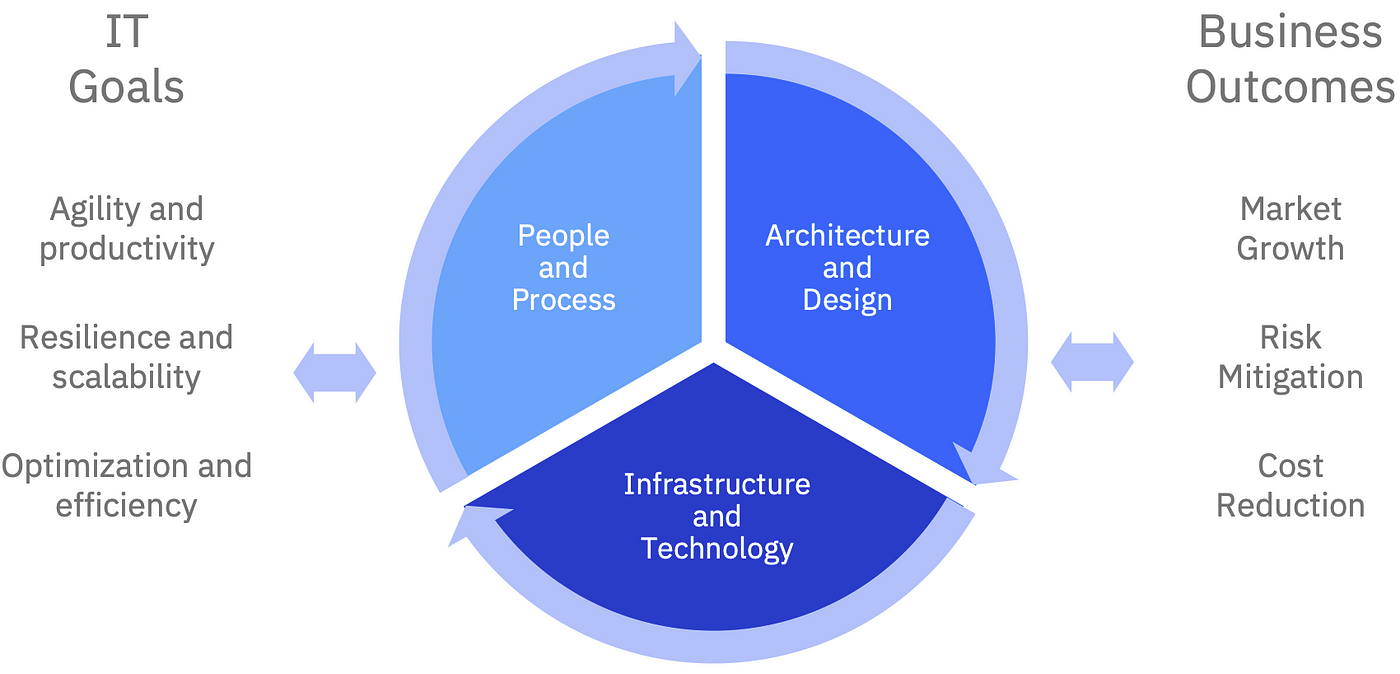
A good example of how these aspects are interlinked, along with warnings as to what happens if the links are broken, is described in our article “Avoiding Incomplete Cloud Native Adoption”. In this article series, we will show how success in cloud native relates the coordination of changes across these three key areas in order to be coordinated in order to succeed: architecture & design, technology and infrastructure, people & process. Lets explore each of these in more detail.
Technology & infrastructure: What is “cloud” in the context of “cloud native”?
A decade or more ago the term “cloud” was largely about location. It usually referred to infrastructure located in someone else’s data center accessible over the internet. However today “cloud” is more a statement about how you interact with that infrastructure. Indeed the location element has all but disappeared as it is now common to have a cloud-like facility that runs on in your own data center — a “private cloud”, as well as hybrid solutions that may involve services and workloads running across both.
So cloud today is more about how you engage with the infrastructure, which at a minimum must provide the following:
- Self-provisioning: Requisition of new virtual resources (servers, storage, networking) instantly.
- Elasticity: Automatically scale resources (and their associated costs) up and down based on demand.
- Auto-recovery: Resources are designed to recover from failures without intervention, and with minimal impact on service availability.
However, as cloud platforms and concepts have matured, the cloud in cloud native really also implies a greater abstraction from the underlying infrastructure.
- Immutable deployment — e.g. container image based deployment
- Declarative provisioning — “infrastructure as code” providing a to-be state
- Runtime agnostic — The platform sees components (e.g. containers) as black boxes, with no need to understand their contents
- Component orchestration — Enable management (monitoring, scaling, availability, routing etc.) through generic declarative policy and provisioning.
In the early years of cloud native, these capabilities were typically highly proprietary, but now this comes almost ubiquitously in the form of containers, and container orchestration capabilities such as Kubernetes. As such, the above list is quite specific to the vocabulary of containers, but it’s worth recognizing that there are other options such as serverless/function as a service that further abstract from the infrastructure, and will likely become more prominent in the future.
We could include more, such as build automation, service mesh, logging, tracing, analytics, software defined networking and storage, etc. However we would then be stepping into what are currently more proprietary aspects of cloud platforms. Hopefully over time these too will become more standardized. So “cloud” in this context really means infrastructure and technology with the special properties listed above.
Architecture and Design: What do we mean by “native” in “cloud native”?
By “native” we mean that we will build solutions that don’t just “run on cloud”, but specifically leverage the uniqueness of cloud platforms. Applications don’t just magically inherit the benefits of the underlying cloud infrastructure, they have to be taught how.
We need to be really careful with language here. When we use “native” to refer to the “uniqueness of cloud platforms”, we do not mean vendor specific aspects of specific cloud providers. That would be “cloud provider native”, and indeed that would go completely against objectives around portability and use of open standards. What we mean is the things that are conceptually common to all cloud platforms. In other words, the things we highlighted in the preceding section on infrastructure and technology.
There are important implications on architecture and design. We need to write our solutions to ensure, for example, that they can scale horizontally, and that they can work with the auto-recovery mechanism. It is here that cloud-native perhaps overlaps most with microservices concepts. This includes for example writing components that:
- minimize statefulness,
- reduce dependencies,
- have well defined interfaces,
- are lightweight,
- are disposable
We will describe these in more depth in our next article, but for now, perhaps the most important thing to note is that they are all highly interdependent. It is much harder, for example to create a component that is disposable if it is highly stateful. Reducing dependencies will inherently help to make a component more lightweight. Having well defined interfaces will enable a disposable component to be more easily reinstantiated, and so on. This is a small example of the broader point that moving to a cloud native approach requires changes on many related fronts simultaneously. These cloud native ingredients we are gradually uncovering are mutually reinforcing.
People and Process: How does “cloud native” change the way we organize and work?
What may be less obvious is that when we work with the above assumptions and decisions about the architecture and underlying infrastructure, it provides us opportunities to radically change the way we handle people and processes. Indeed it could be argued that it necessitates those changes.
Below we’ve explored some of the people/process implications resulting from a microservices approach:
- Microservices implies that you are building your services in small, autonomous teams. This is simply the application of Conway’s Law — if you want your system to be composed of small, decoupled components, then you have to allow your teams to also be small and not tightly coupled to other teams — only allowing formal communication through well defined and governed interfaces.
- Microservices also implies that you are using agile methods and applying DevOps principles to your development processes. If not, how will you gain the end to end feedback and rapid iterations on code that are a core benefit of the approach. DevOps in turn would imply further process improvements such as continuous integration and continuous delivery/deployment (CI/CD).
- DevOps requires you to adopt other specific technical processes such as automated testing (perhaps including test driven development), and strongly leads you toward trunk-based development. The desire to minimize testing cycles might further lead you to explore changing the way you align people to work (e.g. Pair Programming).
Likewise, there is an effect of container technology on required skillsets, roles, and processes:
- The cloud infrastructure generally enables more to be achieved operationally (deployment, scaling, high availability etc.) using generic cloud platform skills such as knowledge of Kubernetes, rather than specific runtime or product skills. This radically reduces the learning curve for people working across multiple technology areas and enabling broader role and knowledge sharing increasing efficiency and reducing cost. It also encourages the shift to site reliability engineers automate operational tasks wherever possible.
- Containers, and specifically container image technology simplify the automation of CI/CD pipelines, leading to shorter build/release cycle time, and increasing productivity. The increased homogeneity of how build pipelines are achieved means they can be more easily maintained, and indeed used by a broader set of people.
- Immutable container images combined with declarative “infrastructure as code” increase the consistency of deployment across different environments. This reduces testing and diagnostics costs, improves speed of deployment, and reduces downtime. From a process perspective this enables a “shift left” of aspects such as reliability, performance and security testing. This in turn enables a more DevOps/DevSecOps culture, where developers have more accountability for the operational qualities of the code.
Summarizing what it means to be “cloud native”
Bringing together what we’ve discussed so far we can see that cloud native needs to be defined from three different aspects.
- Platforms that abstract complexities of the infrastructure. (Infrastructure and Technology)
- Solutions that make best use of the infrastructure abstractions (Architecture and Design)
- Automation of development, operations and business processes, and increasing autonomy of development teams (People and Process)
Today the technology aspect is of course heavily focused on containerization, but it is the properties such as self-provisioning, elasticity, and auto-recovery of that technology that are important, not the technology itself.
Architecturally we most commonly look to microservices principles to create more lightweight, fine grained, state minimized components that map better to abstracted infrastructure. Without the right design principles, our solution will not benefit from the platform. For example, it will not dynamically scale, or offer granular resilience, or offer rapid build and deployment, or have operational consistency with other applications on the platform.
People and process changes are often seen as separate from cloud native, but in reality they go hand in hand, and we consider them part of the defining characteristics. Lack of automation of the software development life cycle will mean a team spends more time on the mundane, and comparatively little time on business value. A heavy, top-down organizational and governance structure will not provide teams the autonomy they need to help the business innovate.
So, with a more concrete definition of what cloud native actually means, we’re ready to take the next step and expand out our previous diagram.
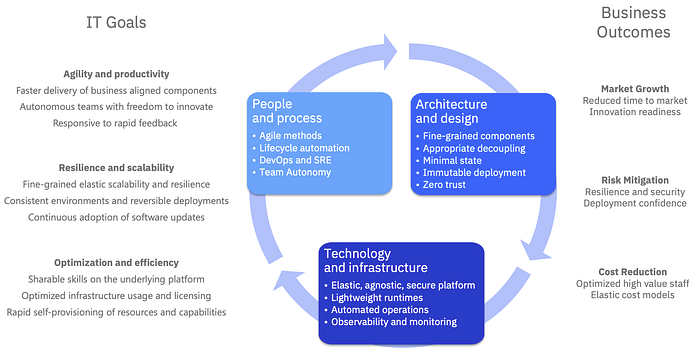
In the diagram above we provide some teasers as to what the key ingredients are in each of these aspects. In subsequent articles of this series, we’ll consider “how” you go about building cloud native solutions and look into each of those ingredients in detail, starting with people and process issues.
However, it should already be clear that to go fully cloud native is non-trivial, and requires business sponsorship. Therefore, in another article we will draw together what we have learned about the commitment required to be successful with cloud native and take a step back to re-consider “why” you might be making the cloud native move in the first place, and what benefits you might hope to achieve.
Acknowledgements
We would like to extend sincere thanks to Holly Cummins and Callum Jackson for their input and review on this article series.